Insights & Updates
Stay up to date with the latest news, tutorials, and insights about voice AI, text-to-speech, and conversational technology.
Automatic Speech Recognition: What a 3B Parameter Model Actually Sounds Like in Production
Here is your article:The Honest Truth About Speech Recognition in 2026If you have ever integrated an automatic speech recognition system into a real product, you already know the feeling. The demo wor...

Real-time TTS API
fonadalabs-tts-v1: A Low-Latency Multilingual Text-to-Speech System for Real-Time Conversational AIMarch 2026We present fonadalabs-tts-v1, a production-optimized multilingual Text-to-Speech (TTS) syst...

Memory and CPU Optimization for Long-Running Audio Streams
Introduction: The Slow Death of a Thousand AllocationsYou have built a beautiful audio streaming service. It is elegant, functional, and for the first hour, absolutely perfect. Then things start to go...

Error Handling Patterns for Audio Processing Services
The 60-Second Timeout: Why Your Audio API's Silent Failures Are Destroying User TrustYour user uploads an audio file to your API. Your server receives it, starts processing, then... silence. No respon...

Backpressure Handling in Streaming Audio Pipelines: A Survival Guide
Introduction: The Traffic Jam Nobody Asked ForImagine you are at a concert, and the sound engineer decides to play every song simultaneously at 10x speed. That is essentially what happens when your st...

Versioning Audio Models Without Breaking Customers
The $500K Model Upgrade: Why Your "Better" AI Just Destroyed 200 Production SystemsYour audio AI model just got dramatically better. New training data, improved architecture, 15% higher accuracy acros...
Building Real-Time Audio APIs Using WebSockets at Scale: Engineering Production-Grade Voice Infrastructure
Picture thousands of simultaneous voice calls, each streaming audio in real-time, expecting processing in milliseconds, demanding near-zero packet loss. This is the reality of building production-grad...

Audio Pre-Processing Pipelines for Voice Bots and IVR Systems: Engineering Robust Conversational AI
You call your bank's customer service. An AI voice greets you instantly. You say "Check my balance" while traffic rumbles outside, and it understands perfectly despite background noise, your accent, a...

Auth, Rate Limits, and Abuse Prevention for Audio APIs
The Day Your Audio API Got Exploited (And How to Prevent It From Happening)You launch your audio AI API with excitement. The product is solid. The documentation is clear. The pricing seems fair. Day o...

Handling Non-Stationary Noise in Indian Acoustic Environments: Real-World Challenges and Solutions
If you've ever attempted a business call from a Mumbai street, tried voice dictation in a Bangalore cafe, or joined a conference from home during Diwali, you understand the challenge. Indian acoustic...

REST vs Streaming APIs for Voice Workloads
REST vs Streaming for Voice AI: Why Your "Simple" Architecture Choice Is Killing Conversational UXYou're building a voice assistant. A user asks a simple question: "What's the weather today?"Your syst...

Designing Clean Audio AI APIs Developers Won't Misuse
Why Developers Keep Breaking Your Audio AI API (And How to Stop Them)You've built an incredible audio AI model. Speech recognition accuracy? Best in class. Voice synthesis quality? Indistinguishable f...

Why Noise Reduction Can Lower Speech-to-Text Accuracy
The Paradox of Perfect SilenceHere's a counterintuitive truth that catches many audio engineers off guard: making your audio "cleaner" can actually make it harder for machines to understand what you'r...

Handling Numbers, Dates, and Special Characters in TTS
The Silent Killer of TTS Quality: Why "Meet me at 5" Breaks Your Voice SystemYou feed a simple sentence to your TTS system: "Meet me at 5."Does it say "meet me at five"? Or "meet me at five o'clock"?...
End-to-End Latency Breakdown in Voice AI Systems
The 3-Second Death: Why Your Voice AI Feels Slow (And Where Every Millisecond Actually Disappears)You ask your voice assistant a question. One second passes. Two seconds. Three. Finally, it responds.T...
Code-Mixed Text-to-Speech Explained
Code-Mixed Text-to-Speech: The Multilingual Challenge Breaking Traditional TTS SystemsPicture this: you're building a voice assistant for the Indian market. Your TTS system handles Hindi beautifully....

The Audio Normalization Problem Nobody Talks About
Why Users Abandon Your Voice AI After 10 Seconds Here's a scenario that's probably costing you users right now: someone calls into your AI-powered customer support system. The automated greeting blast...

Why Noise Cancellation Fails in Complex Acoustic Environments
If you've ever tried taking a business call from a busy street, attempted voice dictation in a crowded cafe, or joined a video conference during a local festival, you know the struggle. Some acoustic...

CPU-Friendly Audio Inference Techniques for Scalable Voice Platforms
Why Your Voice AI App Will Fail at Scale (And How to Fix It Before It's Too Late)Let me paint you a picture you've probably lived through—or you're about to.Your voice assistant app goes viral. Maybe...

How to Measure Voice Naturalness in Text-to-Speech (Why MOS Score Is Not Enough)
If you’re evaluating text-to-speech voices using only MOS scores, you are almost certainly shipping a worse voice than you think.That may sound dramatic. It’s not.It’s a pattern we see repeatedly acro...

Trade-offs Between Neural Vocoders for Production TTS Systems
The magic behind natural-sounding text-to-speech lies in neural vocoders, the algorithms that transform acoustic features into actual audio waveforms. But choosing the right vocoder for production isn...

Building Low-Latency TTS Pipelines for Real-Time Voice Agents
Real-time voice agents live or die by latency. Even a few hundred milliseconds of delay can turn a natural conversation into an awkward, frustrating experience. In this blog, we break down how to build low-latency Text-to-Speech (TTS) pipelines that respond instantly and feel human. From streaming architectures and lightweight neural models to smart chunking and GPU optimization, we explore the techniques that power truly real-time voice interactions. If you’re building voice bots where every millisecond matters, this guide shows how to make your agents speak at the speed of conversation.

From Text to Talk: The Complete Guide to Text-to-Speech Technology
Text-to-Speech has evolved from robotic voices to lifelike, emotional speech that powers accessibility, education, customer support, and multilingual applications. This blog explores how modern neural TTS works, its real-world impact, and how native-language solutions like FonadaLabs are shaping the future of conversational technology, especially for Indian languages.

Single-Channel vs Multi-Channel Noise Cancellation
The Microphone Dilemma: One Ear or Two?Walk into any audio engineering discussion about noise cancellation, and you'll inevitably hit the great divide: single-channel versus multi-channel processing....

How to Improve Audio Quality in VoIP and Telephony: A Guide to Real-Time Noise Suppression
The Symphony of Silence: Why Your Voice Matters More Than EverPicture this: You're on the most important call of your career. Your pitch is flawless, your data is compelling, and then WOOF WOOF WOOF y...

How to Handle Code-Switching and Language Identification in Indian Speech Recognition
If you’ve ever listened to real Indian speech, actual speech, not lab-recorded demo clips, you already know the truth: language boundaries here are messy.A single sentence can start in Hindi, drift in...

Build Your Own Indian Language ASR
Because “बस थोड़ा wait करो” should not crash your appLet’s be honest.If your voice assistant understands “What is the weather today?” but freezes on “कल बारिश होगी क्या?”, your tech is broken.Indian u...
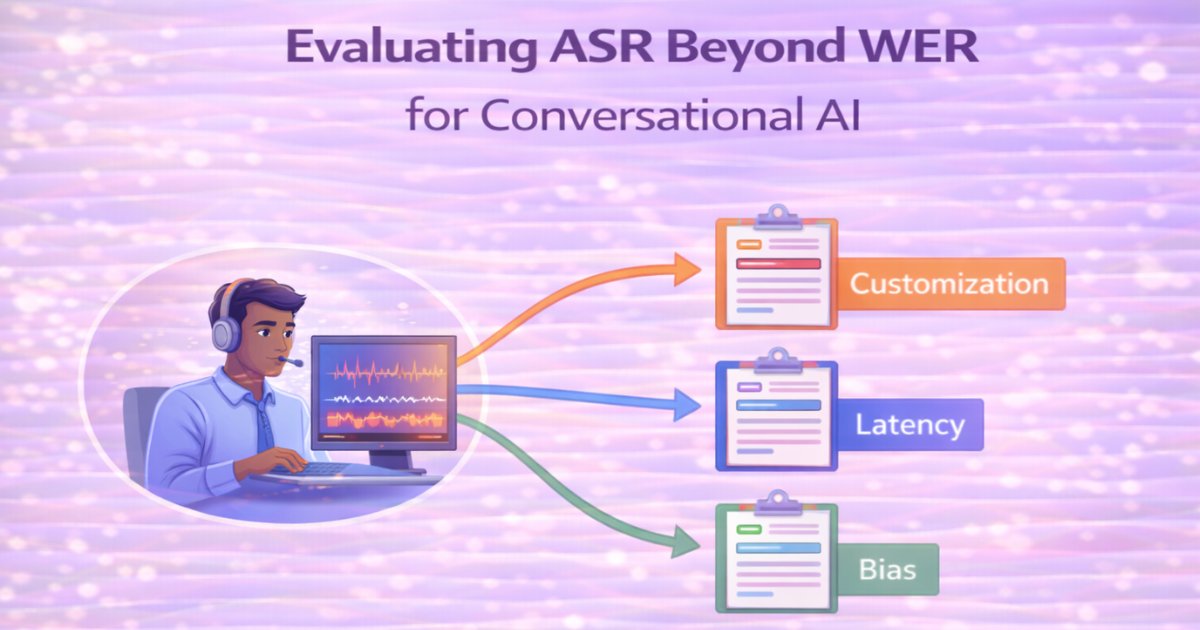
How to Measure Speech Recognition Quality for Chatbots and AI
Word Error Rate (WER) is the industry standard for measuring ASR quality. It's simple, objective, and easy to compare.It's also increasingly useless for conversational AI.WER measures how many words y...

Common Issues and Challenges in Indian Language Speech Recognition
Building ASR for Indian languages is like debugging code where every user speaks a different dialect, half the keywords are borrowed from other languages, and the syntax rules change depending on who'...
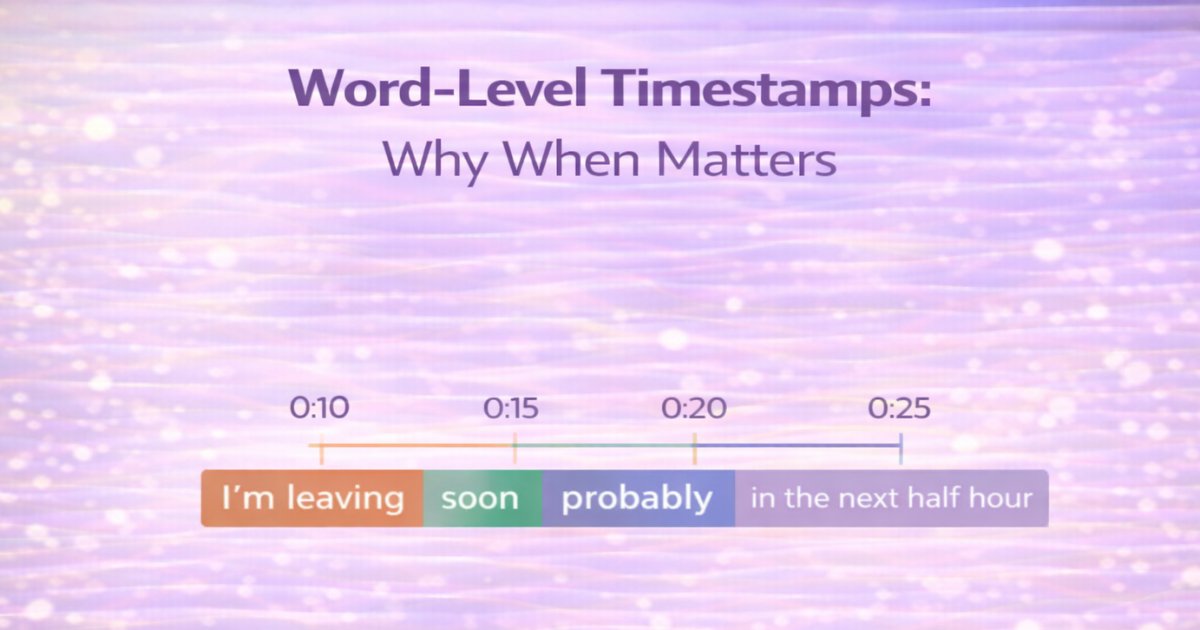
How to Get Word-Level Timestamps in Speech to Text
Speech recognition isn't just about converting audio to text. Knowing when words were said unlocks sentiment analysis that tracks emotional changes, meeting summarization that identifies key moments,...

How Streaming Speech to Text Works: Balancing Speed and Accuracy
Streaming ASR sounds simple: audio flows in, text flows out. Except every decision creates a domino effect. Want lightning-fast responses? Say goodbye to accuracy. Want perfect transcription? Users ab...

How to Improve Speech Recognition Accuracy in Noisy Call Centers
Call center audio is where ASR systems go to die.You'd think call centers would have pristine audio quality. Clear communication is literally their job. But in reality? Absolute nightmare fuel: backgr...

How to Improve Speech Recognition for Indian Accents
If you've ever used a voice assistant that understood your American colleague perfectly but looked completely lost when you spoke, welcome to the accent problem.Here's the thing: accents aren't errors...

How Speech to Text Works: Understanding Accuracy and Challenges
Speech recognition isn’t just about decoding words; it’s about surviving the chaos of real human speech. People mumble, shorten phrases, change direction mid-sentence, and speak through noise, accents, and emotion. Modern systems rely on deep learning, massive datasets, and language context to cope, but gaps remain, especially for accents and spontaneous speech. The real challenge isn’t perfect lab accuracy; it’s working reliably for real people, in real conditions, speaking naturally.

Real-time vs Batch Speech Recognition: Difference, Architecture, and Common Issues
You'd think transcribing speech is transcribing speech, right? Record audio, send it to an ASR system, get text back. Simple.Except it's not.The difference between real-time and batch ASR isn't just a...
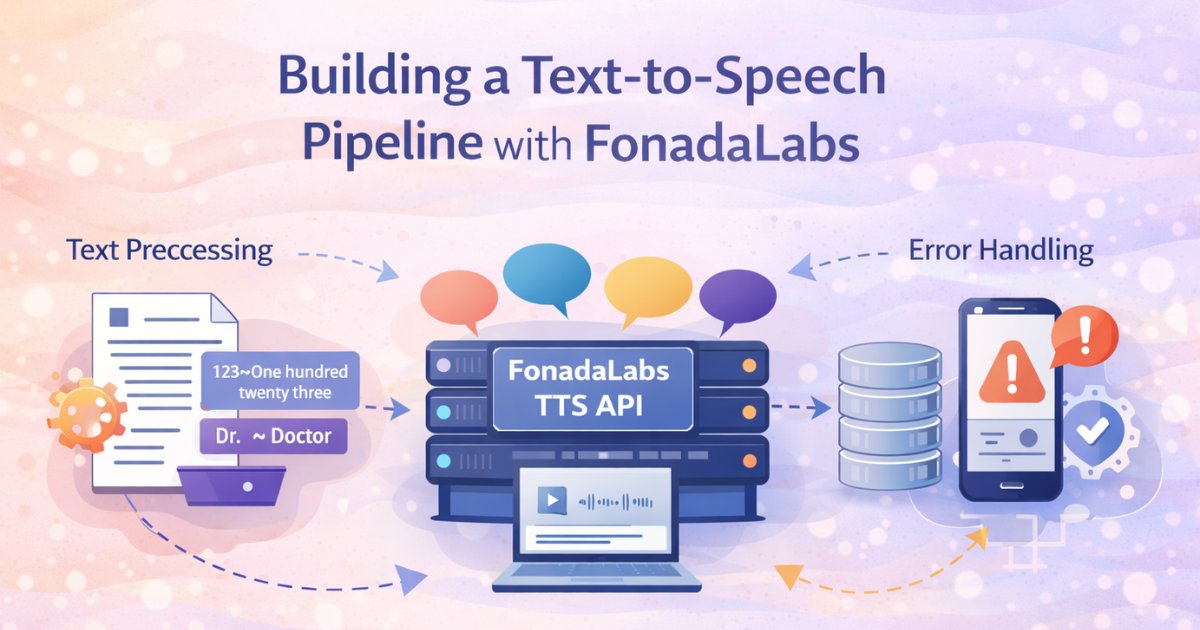
Build Your Own TTS Pipeline: A Quick Start Guide with FonadaLabs
You've decided to add voice capabilities to your application: a customer support bot, educational app, or voice assistant. Good news: building a production-ready Text-to-Speech pipeline with FonadaLab...
We use cookies
We use cookies to analyze site usage and improve your experience. By clicking "Accept", you consent to our use of cookies.Learn more