From Text to Talk: The Complete Guide to Text-to-Speech Technology

Imagine reading a bedtime story to your child through an app while you're away on a business trip. Or picture a visually impaired student "reading" their textbook through their headphones. These scenarios, once science fiction, are now everyday realities thanks to Text-to-Speech technology. But what exactly is TTS, and how has it evolved from robotic monotones to voices so natural you might mistake them for human?
What is Text-to-Speech (TTS)?
Text-to-Speech, commonly abbreviated as TTS, is a technology that converts written text into spoken words. Think of it as a digital voice actor that can read any text you provide, whether it's a single sentence or an entire book, and deliver it as natural-sounding speech.
The Simple Analogy: Imagine you have a friend who's willing to read anything you write. You hand them a note, and they read it aloud. TTS works similarly, except your "friend" is an AI-powered system that never gets tired, can speak in multiple languages, and can even mimic different voices and emotions.
At its core, TTS involves four key steps: Text Processing (analyzing and breaking down text), Linguistic Analysis (determining pronunciation), Prosody Generation (adding natural rhythm and intonation), and Audio Synthesis (creating the actual sound). Modern TTS systems powered by deep learning have revolutionized this process, learning from thousands of hours of human speech to generate remarkably natural audio.
How is TTS Used in Today's World?
Text-to-Speech technology has woven itself into our daily digital lives:
Everyday Applications: Virtual assistants like Siri and Alexa use TTS to respond to queries. GPS apps provide turn-by-turn directions. E-learning platforms make education interactive. Most importantly, TTS makes digital content accessible to visually impaired users, transforming on-screen text into audio.
Business Applications: Customer support systems use TTS in IVR (Interactive Voice Response) to handle queries 24/7. Marketing teams create multilingual voiceovers in hours instead of weeks. Healthcare devices read medication reminders. Banking systems provide automated account information, all powered by TTS.
The Technical Architecture
Modern TTS has evolved through three generations:
Traditional Systems (1990s-2010s) stitched together pre-recorded sound fragments, resulting in choppy, robotic speech. Statistical Systems (2000s-2015) used mathematical models to predict speech pattern, better, but still unnatural. Neural TTS (2016-Present) uses deep learning models that learn directly from human speech, producing remarkably lifelike results.
Today's neural TTS systems use sophisticated architectures like Tacotron and WaveNet. When you input text, it's converted to numerical representations, processed through attention mechanisms that align text with audio timing, transformed into a mel-spectrogram (a visual blueprint of sound), and finally synthesized into high-quality audio through neural vocoders.
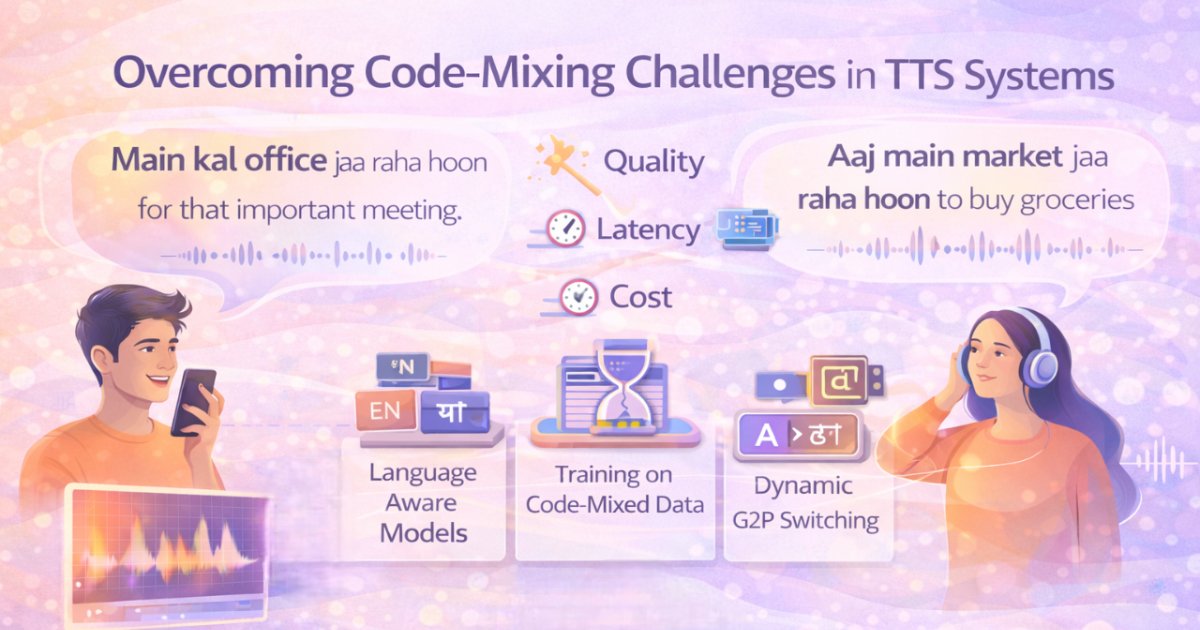
Multi-Language Challenges: Creating TTS for languages like Hindi, Tamil, and Telugu is particularly complex. These languages have intricate scripts, unique phonetic features like retroflex consonants, and regional variations. Users often mix languages (Hinglish), requiring models that handle multiple languages simultaneously. This is where specialized solutions truly shine.
Features and Use Cases
Modern TTS systems offer powerful features: Natural Prosody (understanding that "Really?" sounds different from "Really."), Voice Cloning (mimicking specific voices), Emotion Control (adjusting tone and style), Real-Time Streaming (instant audio generation), and Multilingual Support with seamless language switching.
Real-World Impact: A telecom company reduces customer wait times by 60% using automated TTS responses. An e-learning platform brings education to rural India by converting textbooks to audio in native languages. A news app enables visually impaired users to stay informed. A banking app guides users through complex processes with clear voice instructions. Marketing teams localize campaigns across regions in hours instead of weeks.
FonadaLabs TTS: Natural Speech for Your Applications
FonadaLabs has developed a cutting-edge Text-to-Speech solution built ground-up with native support for English, Hindi, Tamil, and Telugu. Unlike generic TTS solutions that treat Indian languages as afterthoughts, FonadaLabs understands the nuances, pronunciation subtleties, and cultural context that makes speech truly natural.
What Sets It Apart: FonadaLabs delivers lifelike voice quality with natural intonation, clear pronunciation of complex words, and appropriate emotional coloring. The low-latency architecture enables real-time streaming for conversational applications. High-fidelity output meets professional broadcasting standards with minimal artifacts across all supported languages.
Perfect For: Customer support automation (handling queries in preferred languages at scale), educational content creation (converting textbooks to audio lessons), accessibility features (screen readers and voice navigation), interactive voice applications (conversational chatbots and banking services), and media campaigns (rapid multilingual voiceover generation).
Why Choose FonadaLabs: Native language expertise, production-ready quality, scalable infrastructure from startup to enterprise, developer-friendly integration, and cost-effective content generation without recurring voice actor costs.
The Future is Conversational
Text-to-Speech technology has transformed from a robotic curiosity into an essential tool powering accessibility, education, customer service, and countless applications. It's the invisible technology making our digital world more human and accessible.
FonadaLabs TTS represents the cutting edge of this revolution, bringing natural, high-quality speech synthesis to English and Indian languages. Whether you're building customer support systems, creating educational content, enhancing accessibility, or launching multilingual campaigns, FonadaLabs provides the voice technology you need.
The future of human-computer interaction is conversational, and it speaks your language, literally.
Because in the digital age, everyone deserves to be heard, and everything deserves to be accessible.