How to Measure Voice Naturalness in Text-to-Speech (Why MOS Score Is Not Enough)

Why MOS Score Is Not Enough to Measure Text-to-Speech Naturalness (And What Actually Matters)
If you're evaluating text to speech voices using only MOS scores, you are almost certainly shipping a worse voice than you think.
That statement makes people uncomfortable, which it should.
Because this isn’t an edge case. This isn’t a theoretical argument. This is a pattern that's continuing to repeat and repeat and repeat across all these various, various voice systems, customer support, IVRs, educational, accessible, voice assistants, and AI agents and all that nonsense.
Teams follow best practices. They benchmark responsibly. They run listening tests. They select the higher MOS score.
And then the product ships.
A few weeks later, something feels off. User engagement drops. People interrupt the voice more than expected. Sessions end earlier than planned. Support tickets quietly mention that the voice is "robotic," "strange," or "hard to listen to."
What particularly makes this frustrating is that the voice tested well.
This is not a tooling problem. It is not an ML unsophistication problem. It's not a bad vendor decision.
It's a measurement problem and one the industry has normalized for far too long.
Most teams still treat MOS score in text-to-speech as the primary indicator of voice quality. It feels objective. It feels standardized. It feels defensible when questioned by leadership.
But here's the uncomfortable truth most teams only learn after user trust erodes:
Some of the most disliked TTS voices in real-world products have excellent MOS scores.
If you're building anything serious with voice and haven't deeply questioned how you measure TTS voice naturalness, this gap will cost you—quietly, slowly, and expensively.
What Is MOS Score in Text-to-Speech, Really?
MOS, or Mean Opinion Score, is a subjective listening metric that predates modern neural speech synthesis by decades. It originated in telephony and early speech transmission research, where the goal was straightforward: determine whether audio was acceptable after compression or transmission.
A standard MOS test works like this:
Human listeners hear short audio samples—usually between 5 and 15 seconds. They rate each clip on a scale from 1 (bad) to 5 (excellent). The average of those ratings becomes the MOS score.
That's it.
Simple. Quantifiable. Easy to compare.
And that simplicity is exactly why MOS spread everywhere.
"Our TTS voice has a MOS of 4.3." "This system benchmarks higher than competitors."
These numbers sound authoritative. They fit neatly into slides. They give teams a sense of closure—we measured, we chose, we're done.
But here's what MOS actually measures: general audio acceptability in isolation.
What it does not measure is how a voice behaves as part of a real product, over time, under cognitive load, across emotional contexts, or within messy, real-world language.
That difference sounds subtle. In practice, it's the entire difference between a demo voice and a production voice.
Why MOS Became the Industry Standard for TTS Quality
MOS didn't become dominant because it was the best possible way to evaluate speech.
It became dominant because it was convenient.
MOS is:
Easy to run at scale
Easy to compare across vendors
Easy to explain to non-technical stakeholders
In fast-moving product teams, MOS feels like progress. You can benchmark vendors, make a decision, and move on.
But MOS was never designed to evaluate:
Long conversations
Emotional appropriateness
Listener fatigue
Context switching
Code-mixed or multilingual speech
Cultural realism
Real-world usage patterns
Ironically, these are exactly the dimensions that determine whether a voice system succeeds or fails in production.
MOS became the default not because it reflects how humans actually experience voice—but because it fits into procurement workflows, spreadsheets, and RFPs.
That mismatch has consequences.
Why MOS Score Fails to Capture Voice Naturalness
Human speech perception is not one-dimensional.
We don't listen like lab participants rating isolated clips in silence. We listen like humans in the real world:
While multitasking
While tired or stressed
While trying to understand instructions
While waiting for help
While subconsciously deciding whether to trust the system
MOS compresses all of that complexity into a single scalar value.
And that compression hides the very things users care about most.
A high MOS score can coexist with:
Awkward conversational pacing
Emotional mismatch
Subtle uncanny effects
Cognitive fatigue over time
Cultural or linguistic awkwardness
This is why teams are often blindsided when a voice that "benchmarked better" performs worse in production.
To understand why, we need to look at what actually makes a TTS voice feel natural.
What Actually Makes a Text-to-Speech Voice Sound Natural?
Prosody Is the Foundation of Natural Speech
The most significant factor when differentiating between human and synthetic speech is prosody.
It involves pitch changes, stresses, emphasis, rhythm, time, and pauses, and these are determined by meaning, not punctuation.
Humans interpret intent through prosody. If the prosody is off, people sense that something is wrong, without being able to say why.
You may be perfectly accurate in your phonemes and still sound artificial.
Common prosodic failures in TTS include:
Predictable cadence
Pauses that follow commas instead of semantic boundaries
Identical sentence endings
Mechanical emphasis patterns
Short MOS clips rarely expose these issues. Prosodic fatigue emerges over time, which is why prosody must be evaluated deliberately, not inferred from a single score.
Emotional Correctness Matters More Than Expressiveness
Emotion in TTS is often misunderstood.
It's not about making voices expressive or animated. It's about making them appropriate.
A cheerful voice delivering bad news. A flat voice congratulating a user. A friendly tone reading a fraud alert.
These moments don't just feel awkward—they undermine trust.
Users subconsciously expect emotional alignment. When it's missing, the system feels careless or incompetent.
Traditional MOS testing never evaluates emotional correctness. Listeners are asked whether a voice sounds "good," not whether it sounds right for the content.
That gap is small in theory and massive in real products.
Long-Form Consistency Separates Demos From Products
Short demos lie.
As speech continues, small inconsistencies compound:
Gradual pitch drift
Energy fluctuations
Shifts in vocal character
Unstable pacing
You won't notice this in a 10-second clip. You will notice it in:
Audiobooks
Educational narration
Customer support calls
News or podcast-style content
If you're not testing long-form TTS, you're optimizing for first impressions—not sustained experience.
MOS was never designed for endurance testing. This is why building low-latency TTS pipelines requires careful attention to consistency across extended interactions.
Real-World Language Is Messy
Real users don't speak like curated datasets.
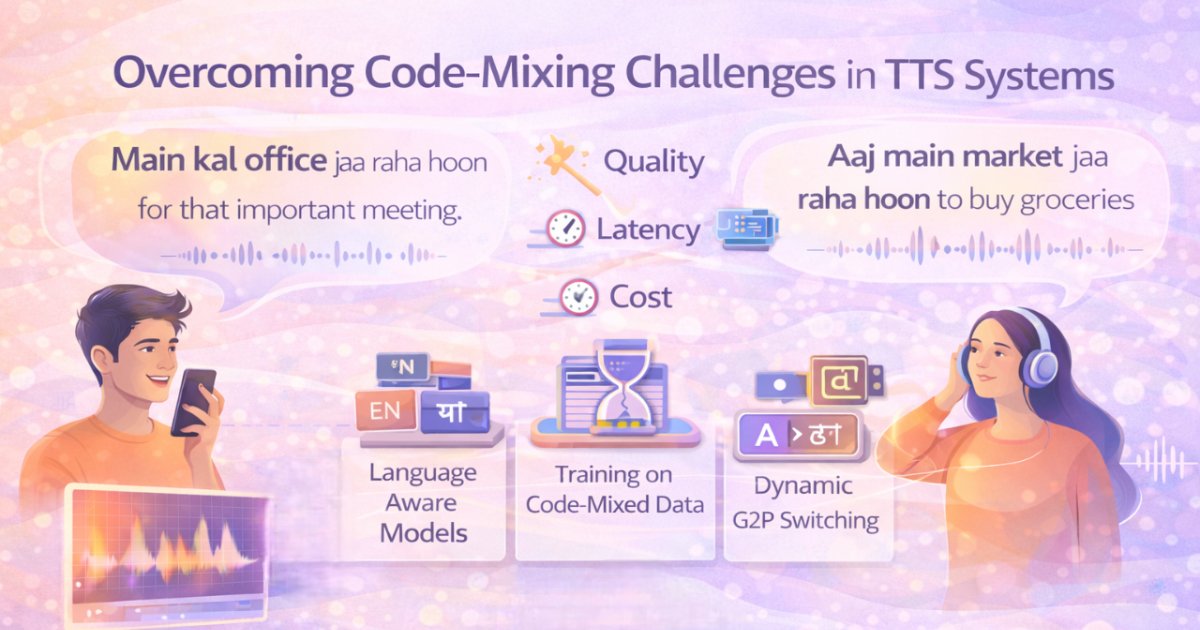
They reference brand names, acronyms, technical terms, slang, and region-specific expressions. In markets like India, they naturally code-mix.
"I need to WhatsApp my CA about GST filing."
This is not edge-case behavior. This is everyday speech.
Supporting Hindi and English separately is insufficient. Code-mixed TTS requires seamless phoneme switching, prosodic blending, cultural familiarity, and context-aware stress patterns.
MOS tests almost never include this reality, which is why systems with "great MOS" still sound wrong to real users.
Why Long-Form TTS Causes Listener Fatigue
Listener fatigue is one of the most underestimated failure modes in TTS.
A voice can sound pleasant for 20 seconds and exhausting after five minutes.
Common causes include:
Over-smooth synthesis
Uniform pacing
Lack of micro-variation
Artificial consistency
Fatigue rarely triggers loud complaints. Instead, it leads to quiet disengagement.
Users stop listening. They interrupt. They abandon sessions early.
MOS does not measure fatigue.
Usage metrics do.
How High-Maturity Teams Measure TTS Quality Beyond MOS
MOS is not useless. It's a baseline.
The mistake is treating it as the truth instead of one signal among many.
Teams that ship strong voice products layer multiple evaluation methods.
They analyze prosodic variability over time. They run intelligibility tests where listeners transcribe speech. They conduct preference-based A/B tests instead of numeric scoring. They examine real production metrics like drop-offs, interruptions, and repeat prompts.
Most importantly, they test voices in real contexts, not sanitized demos. Understanding the trade-offs between neural vocoders is crucial for making informed decisions about production TTS quality.
Where MOS Score Is Actively Misleading
If your product falls into any of these categories, MOS-only evaluation is risky:
Customer support bots, where trust and emotional alignment matter more than polish.
Educational platforms and audiobooks, where fatigue kills engagement long before complaints appear.
Accessibility and assistive TTS, where intelligibility matters more than aesthetics.
Code-mixed and Indian language TTS, where cultural realism outweighs benchmarks.
Why High MOS Does Not Equal Good User Experience
MOS measures how a voice sounds.
Users judge how it feels to live with that voice.
That gap is where most TTS products quietly fail.
Optimizing for MOS optimizes for demos. Optimizing for naturalness builds real products.
Final Thoughts: Why This Matters More Than Ever
Voice is no longer a novelty feature.
It's an interface.
And interfaces shape trust.
When a voice feels unnatural, users don't complain loudly. They disengage silently. They stop listening. They stop trusting. They stop using the product.
If you're still measuring TTS naturalness primarily through MOS, you're already behind teams that understand speech is multi-dimensional.
This isn't an argument to abandon MOS.
It's a warning not to mistake it for reality.
Because the voices that win aren't the ones with the highest scores.
They're the ones users forget are machines.
And missing that insight is far more expensive than missing a benchmark. If you're ready to build your own TTS pipeline with naturalness as a core design principle, start with comprehensive evaluation methods from day one.