How to Get Word-Level Timestamps in Speech to Text
Speech recognition isn't just about converting audio to text. Knowing when words were said unlocks sentiment analysis that tracks emotional changes, meeting summarization that identifies key moments, and speaker attribution that knows who said what when.
Without timestamps, transcripts are walls of text in temporal ambiguity. With them, they're structured data you can slice, analyze, and build on.
What They Are
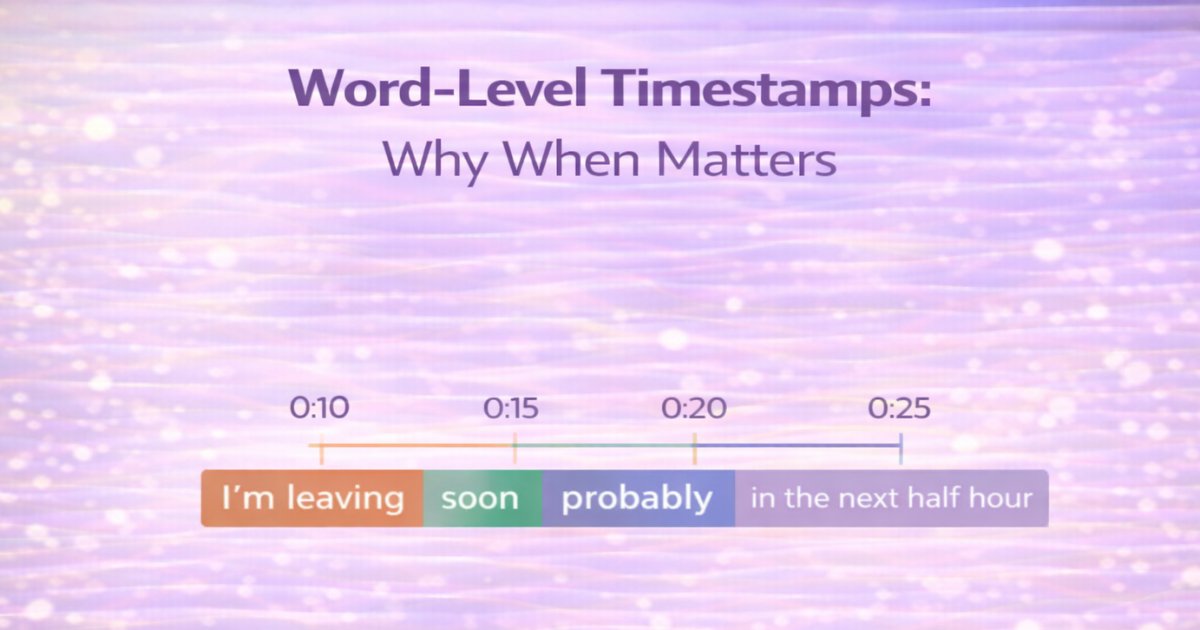
Basic: "Hello, my name is Priya and I need help with my account"
Timestamped: [0.00-0.50] Hello, [0.51-0.89] my, [0.90-1.20] name... [3.66-4.20] account
Why it's hard: ASR maps audio to phonemes/subword units, then constructs words via language models and beam search. By the time you have words, you've lost direct connection to audio frames. Reconstructing timestamps requires expensive alignment tracking, force-alignment (adds latency), or specialized architectures. Word boundaries are fuzzy ("I am" sounds like "I'm"), silence isn't reliable (people pause mid-word or run words together), and overlapping speech has no standard handling.
Critical Applications
Sentiment over time: Customer support call starts neutral, frustrated at 2:30 (can't find account), angry at 4:15 (on hold), satisfied at 6:00 (resolved). Without timestamps: "mixed sentiment." With timestamps: pinpoint when things went wrong, correlate with actions. Critical for QA and agent evaluation.
Speaker attribution: Create per-speaker transcripts, attribute quotes in summaries, track contributions, identify interruptions.
Search & navigation: "Budget concerns" in a 2-hour meeting become clickable links jumping to exact moments. Transforms unsearchable recordings into navigable content.
Summarization: Weight recent content, identify topic transitions, distinguish discussion from conclusions, extract time-anchored action items.
Compliance: Financial services, healthcare, legal proceedings require proving not just what but when. Timestamps provide verifiable records.
Real-time captions: Live video needs frame-accurate synchronization or the experience breaks.
Technical Challenges
Alignment drift: 10ms error per word = 1 second after 100 words = 30+ seconds off after 1 hour. Caused by audio preprocessing, feature extraction limits, and decoding uncertainty.
Streaming tradeoffs: Real-time ASR emits partial timestamps that change as more audio arrives. Solutions: only emit finals (latency), send updates (complexity), or accept approximates (reduced utility).
Overlapping speech: When speakers overlap, do you timestamp both independently (overlapping), adjust to eliminate overlap (inaccurate), or split words into segments (complex)?
Granularity: Choose What You Need
Word-level: Maximum flexibility, can aggregate but not subdivide. Cost: more data, more errors. Phrase-level: Cleaner, fewer timestamps, can't reference individual words. Sentence-level: Simple, compact, too coarse for many tasks. Segment-level: Extremely simple, insufficient for most NLP.
More granularity isn't always better; choose based on your use case.
Downstream Pipeline Uses
Time-aware NER: Track how entities evolve, associate entities with specific moments, extract temporal relationships.
Temporal sentiment: Calculate sentiment at intervals via sliding windows over timestamped words to create sentiment timelines.
Topic segmentation: Timestamps identify pauses, prosodic changes, and rhythm shifts marking topic boundaries.
Event extraction: Anchor events to specific times with semantic and temporal information.
Dialogue act classification: Temporal patterns help classify questions, answers, commands (questions have rising intonation correlating with timing).
Storage Considerations
Timestamps add overhead, 1-hour transcript: 10KB plain, 100KB+ with word timestamps. Common formats: JSON with embedded timestamps, WebVTT for subtitles, custom compressed formats. Timestamp precision: 10ms for captions, 1ms for compliance, maximum for research. Choose based on requirements, not "more is better."
The Bottom Line
Word-level timestamps transform transcripts from static text into temporal data, enabling sentiment analysis, speaker attribution, search, summarization, compliance, and captions that don't work without temporal information.
Yes, they're technically challenging. Yes, they add overhead. Yes, they complicate pipelines. But if you're building anything beyond basic transcription, you need them.
The difference between plain text and timestamped text is the difference between a transcript and a dataset. One is useful for reading. The other is useful for building on. In modern NLP pipelines, temporal context isn't optional, it's fundamental.
Choose your ASR system accordingly. If timestamps are an afterthought or missing, you're limiting what you can build. If they're designed with accuracy and usability, you're set up for success.
Speech isn't just words. It's words in time. And time matters.
FonadaLabs' ASR API returns timing information as part of transcription responses, providing the temporal data needed for production NLP pipelines working with real conversational data.